You should not use URLPattern to route HTTP requests on the server
Node.js is adopting the `URLPattern` spec, but its regex-based routing can be slow.
URLPattern is a Web Specification, which recently landed in Node.js thanks to the outstanding work of Yagiz Nizipli and Daniel Lemire in Ada v3. It will soon be available in Node.js v23.
You can see the evolution of the spec at https://github.com/whatwg/urlpattern. The API was designed with client side routing in mind and did not consider the use case of servers and the learnings of running Node.js at scale for many years.
The Problem
URLPattern was designed around the path-to-regexp module, which is the basis of the popular express framework.
All the analyses I will do apply to both - and all other libraries that apply the same concepts.
URLPattern and path-to-regexp converts path patterns into regular expressions that are then matched against actual URLs.
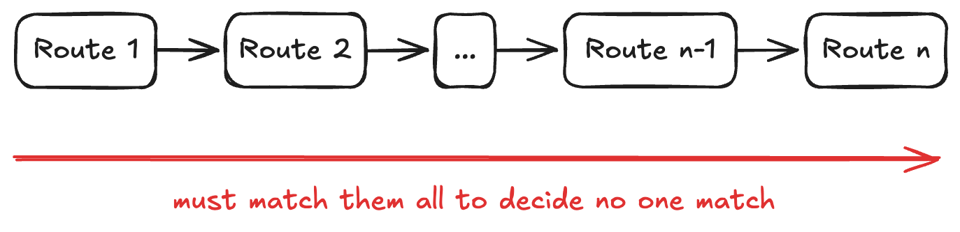
Therefore, if you have 100 routes, your router will test your incoming URL with all the regexps, in order. This is very flexible.
The problem arises to assess URLs that are not going to match: m regexps have to be tested, where m is the number of routes. How costly is to test a regular expression? Let’s measure: on my system, it takes 7.25ns to match a RegExp. I used this code:
import { run, bench } from 'mitata'
const a = new RegExp('a')
const b = new RegExp('b')
function test(regexp) {
return regexp.test('a')
}
bench('success', () => test(a));
bench('failure', () => test(b));
await run();
Doing some napkin math:
- 1 second = 1,000,000,000 nanoseconds
- Tasks per second = 1,000,000,000 ÷ 7.2 = 137,931,034.48
You can perform approximately 137.9 million regexp matches per second at best. This seems high! However, if we add 100 routes, we could only perform 1.38 million checks per second in the best case, which doesn’t look suitable for our application performance in the case of the most complex routing scenarios.
In the case of URLPattern, things are even more complicated as the URLPattern spec heavily relies on regex ECMAScript syntax. Users can specify a pattern for each URL component; therefore, for a single URLPattern,, more than one regular expression would need to be tested. There isn’t any solution that is fast, secure, and fully implements ECMAScript regex syntax outside of ECMAScript runtimes. Therefore, Ada makes it pluggable so that Node.js can use V8 regexp engine.
Ada URLPattern is not optimized at the moment, and if it’s the fastest, it will still be slow due to the regexp matching bottleneck.
The security problem with mapping to regular expression
Mapping to regular expression is essentially unsafe, as it opens the way for Denial of Service attacks. Even modules like path-to-regexp that have been in use forever are found potentially vulnerable to these attacks, as CVE-2024-45296 shows.
Modules such as safe-regex and safe-regex2 can be used to test the safety of a RegExp.
"URLPattern is based on an old, insecure, and poor performing approach from the early days of Node.js and Express. The ecosystem has found better ways to do high-performance routing since then, and even modern versions of path-to-regexp and Express are moving away from the regular expression based routing, leaving the spec even further behind." - Wes Todd, Express Technical Committee & Node.js Platform Team @ Netflix
Routing is a Computer Science problem!
Luckily, these kind of problems have been extensively studied. Let’s consider our beloved web servers, and see what properties we can observe:
- most routes have some prefix in common with other routes, e.g.
/categories/42and/categories/42/posts. - the input string is limited in length, as most web server put a limit to prevent attacks
/usually indicates some “hierarchy” between the various routes, to the point that developers often labels them as “folders”.
Based on these concepts, we could design several data structures and algorithms that can help reduce the search space for matching routes massively. One of those data structures is the trie, and specifically a radix prefix trie.
How does a radix prefix trie work
A trie (pronounced "try") is a tree data structure used to store and retrieve strings, where each node typically represents a single character and the path from the root to any node represents a string prefix. Unlike a binary tree, each trie node can have multiple children - one for each possible character in the alphabet. This structure makes tries excellent for tasks like looking up words in a dictionary or autocomplete.
A radix prefix trie is a compressed version of a regular trie that optimizes space by merging nodes with only one child. Instead of storing a single character per node like a regular trie, each node in a radix trie can contain a string segment, making it more memory-efficient while maintaining fast lookups. For example, storing the words "romantic", "rome", and "romulus" in a regular trie would require separate nodes for each character (r->o->m->a->n->t->i->c). However, a radix trie would compress this into just four nodes: a root node and three children containing "rom", followed by branches for "antic", "e", and "ulus".
The key operations (insertion and lookup) work by traversing the tree and finding the longest matching prefix at each step. When inserting, if a partial match is found, the existing node may need to be split to accommodate the new word. This makes radix tries particularly efficient for applications like IP routing tables, file systems, and autocomplete features where strings often share common prefixes.
find-my-way
Back in 2016, Tomas della Vedova and myself wrote find-my-way, which is the router of Fastify.
It supports:
- static routes
- parametric routes
- multi-parametric routes
- regexps routes (within two
/) - wildcard routes
Here is a basic example:
const http = require('http')
const router = require('find-my-way')()
router.on('GET', '/:name', (req, res, params) => {
res.end(`hello ${params.name || 'world'}`)
})
const server = http.createServer((req, res) => {
router.lookup(req, res)
})
server.listen(3000, err => {
if (err) throw err
console.log('Server listening on: http://localhost:3000')
})
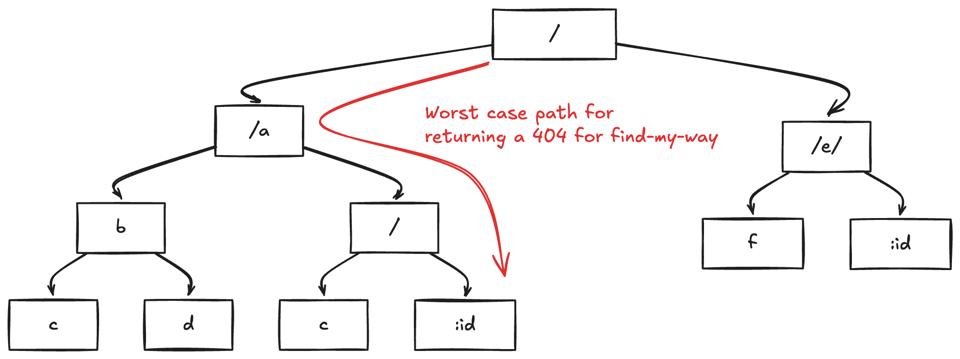
Note that find-my-way is only an implementation of the Trie data structure. Most other implementation would have similar performance characteristics. Thanks to AI, I recommend to build your own and verify.
Benchmarks
Currently, find-my-way is around 100x faster than URLPattern in the worst case as you can see in https://github.com/mcollina/router-benchmark/pull/1.
$ ../node/node benchmarks/urlpattern.js
======================
URLPattern benchmark
======================
short static: 93,917 ops/sec
static with same radix: 78,948 ops/sec
dynamic route: 54,797 ops/sec
mixed static dynamic: 35,589 ops/sec
long static: 28,652 ops/sec
wildcard: 26,679 ops/sec
all together: 6,944 ops/sec
$ ../node/node benchmarks/find-my-way.js
=======================
find-my-way benchmark
=======================
short static: 20,083,987 ops/sec
static with same radix: 6,528,001 ops/sec
dynamic route: 3,239,884 ops/sec
mixed static dynamic: 4,098,899 ops/sec
long static: 4,038,037 ops/sec
wildcard: 5,154,407 ops/sec
all together: 742,587 ops/sec
Thankfully, Yagiz promised me that he would optimize URLPattern further. Hopefully, it will help close the performance gap. However, it would be impossible to beat the fundamental advantages of a prefix trie.
URLPatternList to address the gap
URLPatternList is a draft specification proposed by Luca Casonato in 2022 to address this problem, but it hasn’t progressed further in the last two years. I hope we also add this to Node.js because without it, URLPattern is essentially useless on the server. Hopefully, Ada will get a matching implementation, enabling a massive speedup.
Why does this problem matter to me
I care about Node.js being viable for production loads and fast enough to saturate a virtual network card, as found in most cloud providers. In 2016, I started working on fastify, and routing was one of the problems we investigated and addressed successfully.
Around 7 years ago, I explained this problem (and more) in my “Take your HTTP server to ludicrous speed” talk, which I did at Node.js Interactive in Vancouver in 2017.